THINK Blog DACH
Fehlersuche durch alle Instanzen: Observability-Lösung macht die elektronische Gerichtsakte (wieder) performant

Gerichtsprozesse sind eine komplexe Angelegenheit. Fakten müssen ermittelt werden, Spuren nachverfolgt, Zeugen und Beteiligte verhört werden, bevor ein Urteil gefällt werden kann. Und all das...
Gerichtsprozesse sind eine komplexe Angelegenheit. Fakten müssen ermittelt werden, Spuren nachverfolgt, Zeugen und Beteiligte verhört werden, bevor ein Urteil gefällt werden kann. Und all das erfolgt meist noch auf Basis von umfangreichen Papierakten. Durch die gesetzlich verankerte Einführung der elektronischen Akte (eAkte) bis zum Jahr 2026 soll nun die Digitalisierung in der Justiz vorangetrieben und Richter, Staats- und Rechtsanwälte entlastet werden. Doch was passiert, wenn die eAkte einfach nicht funktionieren will und im Gerichtsalltag abstürzt? Genau das geschah einem Kunden von IBM, nachdem der landesweite Rollout der eAkte an allen Gerichten begonnen hatte.
Wie bei so vielen (IT-)Projekten hatten sich alle Beteiligten im Vorfeld viele Vorteile versprochen: Schnellere Prozessabläufe durch übersichtlichere, schnell durchsuchbare digitale Prozessakten statt dicker Papierstapel. Dafür hatte ein Landesjustizministerium ein Projekt ins Leben gerufen, um die eAkte zu entwickeln und dann einzuführen. IBM war einer der IT-Dienstleister, die in das Projekt eingebunden wurden und übernahm die Entwicklungs- und Wartungsaufgaben.
Nach 2,5 Jahren im Betrieb funktionierte die eAkte auf einmal nicht mehr ganz so reibungslos wie geplant. Es kam zu Systemausfällen und wiederkehrenden Performanceproblemen beim Arbeiten mit der eAkte. Kunde und Dienstleister standen vor einem Problem: denn die eAkte lief nicht nur einfach nicht mehr performant – niemand wusste, wo die Performanceprobleme ihren Ursprung hatten.
Die eingesetzte IT-Umgebung ist sehr komplex, teilweise Cloud-basiert und besteht aus vielen Servern, zusätzlichen virtuellen Servern, Hypervisoren und verschiedenen Containern. Und diese wiederum gibt es für die vielen unterschiedlichen Bereiche der Justiz: wie z.B. für die ordentliche Gerichtsbarkeit, die Fachgerichte oder für die Staatsanwaltschaften. Für all diese Bereiche ist die eAkte jedoch organisationskritisch und ihr Funktionieren daher ein Muss. Eine schnelle Stabilisierung des Systems war somit essenziell.
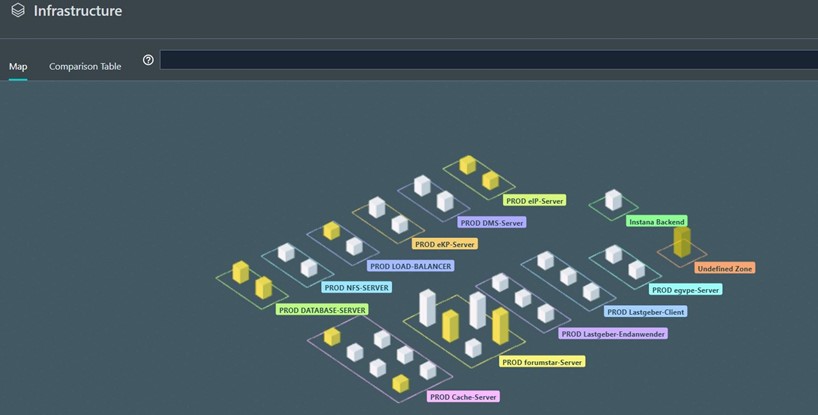
Die IT-Landschaft des eJustice-Systems der eAkte im Überblick
Die Fehleranalyse erwies sich in dieser Systemlandschaft mit ihren vielen Instanzen und Architekturschichten als extrem zeitaufwändig. Die eingesetzten Analysewerkzeuge und Monitoring-Tools beleuchteten nur Teilaspekte, da sie zumeist nur für einzelne (Hintergrund-)Systeme optimiert sind. Die Probleme entstanden jedoch auf der Anwendungsebene und jedes der zahlreichen Backend-Systeme konnte der Auslöser sein. Moderne IT-Umgebungen sind oft sehr unübersichtlich: Die schleichende Umstellung auf Multi-Cloud-Umgebungen, Microservices, Container, Kubernetes und das fast unermessliche Wachstum der Datenmengen erzeugen eine Komplexität, der die Systemadministratoren in IT-Abteilungen immer seltener ohne zusätzliche Hilfsmittel gewachsen sind.
Auch hier waren unterschiedliche Spezialisten aus den verschiedenen Bereichen nötig, um die zahlreichen Analyse-Daten zu verstehen und zu interpretieren. Sie mussten außerdem in der Lage sein, die Daten zu korrelieren, um den Ursprung des Problems in der hochkomplexen eJustice-Umgebung zu identifizieren. Hinzu kam, dass die erkannten, notwendigen Änderungen nur mit langen Vorlaufzeiten umgesetzt werden konnten.
Alte Zöpfe abschneiden
Um die eAkte zum Laufen zu bringen, mussten nun zwei Dinge geändert werden: Erstens wurde die bisherige Zusammenarbeit neu organisiert. Alle Beteiligten mussten über bisherige Organisations- und Verantwortlichkeitsgrenzen in den Behörden hinweg zusammenarbeiten. Zweitens wurde eine IT-Lösung benötigt, die über die Möglichkeiten der bisherigen Analysewerkzeuge deutlich hinausging. Sie musste in der Lage sein, ein Gesamtbild der laufenden IT-Prozesse und ihrer Performance über das gesamte IT-System der eAkte hinweg zu liefern.
Um die Kooperation zwischen den Beteiligten zu optimieren, wurde zunächst eine spezielle Taskforce gegründet, die das Performance-Problem gezielt angehen sollte. In dieser Taskforce arbeiteten Ministeriumsangestellte, das Justizteam des zentralen IT-Dienstleisters des Bundeslandes sowie die externen Experten_innen der eingebundenen Unternehmen direkt zusammen. Dadurch, dass nun alle Beteiligten an einem Tisch saßen, wurden die Reaktionszeiten beim Auftauchen von Problemen deutlich kürzer. Nachdem diese eine Change-Aufgabe im Team bewältigt war, musste für die zweite Herausforderung noch eine geeignete Lösung gefunden werden. IBM brachte daher die hauseigene Software IBM Instana ins Spiel, eine Observability-Lösung für das Application Performance Monitoring.
Dank Agenten alles im Blick
Observability-Lösungen klinken sich über kleine Monitoring-Programme, die sogenannten Agenten, in verschiedenste Systeme ein. Dann überwachen sie diese fortlaufend und führen alle gesammelten Daten zu einem Gesamtbild zusammen. Dazu gehören dann z.B. Informationen aus Anwendungen, Datenbank-Dumps, Auslastung realer und virtueller CPUs sowie aus diversen Microservices, einzelnen Containern oder dem Kubernetes-System als Ganzes. Sie ermöglichen so einen tieferen, ganzheitlichen Blick auf die IT-Landschaft und zeigen auf, warum und wo Probleme auftreten und welche Systeme oder Anwendungen genau die Auslöser sind.
Die neueste Generation solcher Observability-Lösungen kann auch Cloud-native Anwendungen verwalten. Die Anwendungen können sich auf mobilen Geräten, in öffentlichen und privaten Clouds oder vor Ort im eigenen Rechenzentrum oder auch einem Großrechner befinden. Sie bauen selbstständig ein kontextbezogenes Verständnis von Anwendungen auf und liefern dem IT-Team dann automatisch Informationen und Lösungsvorschläge zu möglichen Problemen wie langen Antwortzeiten oder ausgefallenen Infrastrukturen. So kann die IT rechtzeitig eingreifen, bevor ein Schaden für das Unternehmen entsteht oder Kunden unzufrieden werden.
Ressourcen-Diebstahl in der Infrastruktur der eAkte
Nachdem das Team die neue Lösung bei dem zentralen IT-Dienstleister des Landes installiert und in Betrieb genommen hatte, konnte das Problem rasch eingegrenzt werden. Die Analysen zeigten, dass es bei zwei Dokumentenmanagementsystemen (in der Grafik: prodalf01 im blauen Graphen und prodalf02 im grünen Graphen) in der eJustice-Umgebung konstant wiederkehrende CPU-Steals gab (siehe Grafik 3). Die virtuellen CPUs dieser Systeme warteten also auf Rechenzeit der echten CPU, die aber gerade Berechnungen für andere virtuelle CPUs ausführten. Das korrelierte mit einer hohen CPU-Load auf den betroffenen Servern, die Prozessoren waren überlastet. Das führte dann zu den Performancestörungen, die für den Systemausfall verantwortlich waren.
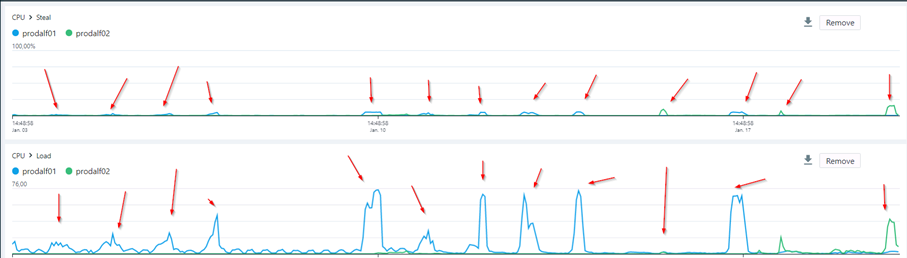
Sichtbarer zeitlicher Zusammenhang der Spitzen bei CPU-Steal und CPU-Load
Wenn der Detailgrad erhöht und das Zeitfenster weiter auf nur einen Tag des Systemausfalls eingegrenzt wird, dann wird der Zusammenhang der Störung noch deutlicher.
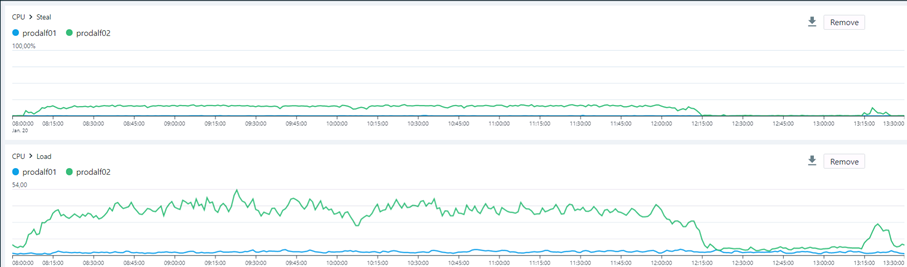
Die CPU-Steal lag in der Zeit der Störung von ungefähr 8:00 Uhr bis 12:15 Uhr auf dem aktiven System (prodalf02) konstant zwischen 15% bis 17%. Dies korreliert mit der CPU-Load und den zur gleichen Zeit beobachteten, stark einbrechenden Antwortzeiten der Backend-Komponenten. Dieses Symptom sorgte dann im Gesamtsystem für eine fatale Verkettung von Ereignissen. Das Team konnte zudem beobachten, dass weitere Systemkomponenten der eJustice-Umgebung in Time-outs liefen, da festgelegte Antwortzeiten nicht eingehalten wurden. Basierend auf diesen Erkenntnissen folgten weitere Untersuchungen auf dem Hypervisor, die ein generelles Konfigurationsproblem bei der Ressourcensteuerung aufdeckten. Zudem zeigte sich dieses Problem in der gesamten Hypervisor-Infrastruktur und bedurfte einer Korrektur.
Ohne einen ganzheitlichen Blick auf die eJustice-Umgebung hätte das Team diesen Fehler nicht annähernd so schnell gefunden. Allein das Zusammentragen der benötigten Informationen hätte vermutlich Tage gekostet. Nach dem ersten Einsatz der Observability-Lösung gelang es hingegen, innerhalb von vier Tagen eine Lösung zu finden und diese dann umgehend zu implementieren. So konnte das IT-Team die eAkte dann schnell wieder zurück in die Gerichtssäle bringen.