THINK Blog DACH
Accountable Federated Machine Learning – wie Modelle ohne Datenzugriff überprüft werden

By Jerry M. Chow, Oliver Dial, and Jay Gambetta Die öffentliche Verwaltung ächzt unter langwierigen Prozessen. Nicht umsonst ist es in Deutschland fast schon ein Volkssport, sich über die...
By Jerry M. Chow, Oliver Dial, and Jay Gambetta
Die öffentliche Verwaltung ächzt unter langwierigen Prozessen. Nicht umsonst ist es in Deutschland fast schon ein Volkssport, sich über die langsamen Mühlen in deutschen Behörden zu beschweren. Doch geht der technologische Fortschritt auch an der oft als zu verstaubt empfundenen deutschen Bürokratie nicht vorrüber. Besonders Machine Learning kann helfen, Prozesse datengetrieben zu vereinfachen und zu beschleunigen. Eine große Hürde sind dabei nicht die Algorithmen, sondern vielmehr die benötigten Daten unter Einhaltung von Rechtsnormen wie DSGVO. Deshalb arbeiten IBM und fortiss, im Rahmen des „Center for AI”, an Accountable Federated Machine Learning-Projekten, kurz AFML, bei denen der Datenschutz penibel eingehalten wird und dennoch valide Ergebnisse entstehen.
Wie funktioniert Federated Machine Learning?
Um ein Machine Learning-Modell erstellten zu können, braucht es Daten – und zwar möglichst viele und detaillierte. Oft steht der Datenschutz dem im Weg. Also muss ein Weg gefunden werden, bei dem die Modelle gut genug trainiert werden können, um erfolgreich zu arbeiten, während gleichzeitig strikte Vorgaben eingehalten werden. Hier kommt das sogenannte Federated Machine Learning ins Spiel.
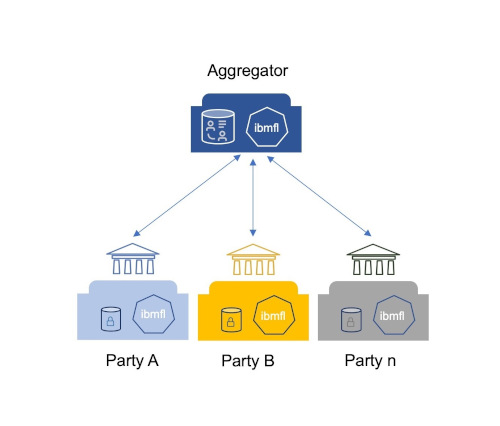
Beim Federated Machine Learning lernt ein Algorithmus aus strikt getrennten Datensätzen. Dabei werden die eigenen Daten von jedem Teilnehmer (oder jeder Partei) selbst verwaltet und lokal gespeichert. In einem solchen AFML-Projekt für die deutsche öffentliche Verwaltung mit mehreren deutschen Städten hat IBM gemeinsam mit fortiss diesen Ansatz gewählt. Ziel war es, einen Ideenklassifikator als Prototyp zu erstellen, der erkennt, wie Einwohner ihre Bürgerideen, mit denen sie sich aktiv in die Gestaltung der Städte und Gemeinden einbringen können, formulieren. Der Machine Learning-Algorithmus hilft im Anschluss, alle Bürgerideen schneller zu klassifizieren und somit zügiger beantworten zu können. Da die einzelnen Städte ihre Daten nicht weitergeben dürfen, haben sie jeweils ein eigenes Modell mit ihren Daten trainiert. Diese Ergebnisse haben die Städte dann anhand eines vordefinierten Ablaufprotokolls an einen Aggregator weitergeleitet. Der Aggregator hat wiederum alle eingesendeten Informationen gesammelt und aus dem Input aller Städte ein Machine Learning-Modell entworfen, das zurückgespielt werden konnte.
Mehr zum Thema Federated Learning erfahren Sie im Data Science Podcast mit Nathalie Baracaldo:
Das Modell muss Rechenschaft ablegen
Ein wesentlicher Punkt eines jeden Machine Learning-Modells ist seine Transparenz und Erklärbarkeit. Vor allem im Hinblick auf den Einsatz im behördlichen Rahmen war es wichtig, nachvollziehen und nachweisen zu können, wie das Modell entstanden ist. Die Frage nach der Accountability, also wie genau und wie vertrauenswürdig das Modell ist, wurde von IBM im nächsten Schritt gemeinsam mit fortiss angegangen. Getreu dem Motto „Trust but Verifiy“ wurde ein Accountability Framework entworfen, der die Überprüfung des Modells im Hinblick auf Reproduzierbarkeit und auf eventuelle Fehler, die beim Training unterlaufen seien könnten, ermöglicht. Außerdem musste geklärt werden, ob ein Bias vorliegt (sei es im Hinblick auf das Geschlecht, die Herkunft oder den sozioökonomischen Status der Bürger). Ebenso, ob das Modell fair ist oder in irgendeiner Weise manipuliert wurde.
Da bei einem Federated Machine Learning-Modell die Rohdaten nicht vorliegen, ist es schwierig das Modell zu verifizieren. Zwar kann dem System des Federated Learning grundsätzlich vertraut werden. Um aber Rechenschaft über das spezielle Modell ablegen zu können, wurden von IBM und fortiss diverse Behauptungen, sogenannte Claims, mittels der Evidentia-Technologie aufgestellt. Diese beziehen sich auf diverse Punkte des Modells, wie zum Beispiel der Ablauf des Training-Prozesses oder die aufbereiteten Daten. Die Verifizierung dieser Claims ist die Accountability, also die Rechenschaftsprüfung des Modells, die auch Dritten wie beispielsweise Auditoren zugänglich ist.
Von der Fragestellung bis zur Überprüfung
Der gesamte Prozess des Accountable Federated Machine Learning besteht aus vier Schritten, an deren Ende die Überprüfung (das Audit) des Modells steht. Im ersten Schritt gilt es, das Projekt aufzusetzen und sich über das Ziel und die eigentliche Fragestellung bewusst zu werden. Es gilt zu klären, was konkret mit dem Projekt erreicht werden soll. Im Pre-Processing werden dann die Daten ausgewählt, die in das Modell inkludiert werden sollen. Dann folgt das eigentliche Training des Modells und im Post-Processing wird schließlich entschieden, wie es konkret eingesetzt werden soll.
So simpel diese vier Schritte klingen, so komplex ist die eigentliche Umsetzung. Es gibt viele Stolpersteine, die das finale Modell negativ beeinflussen können. Der bereits genannte Bias in den Daten kann die Qualität beeinflussen. Aber auch unterschiedliche Datensätze, die dazu führen das einzelne Teilaspekte über- oder untertrainiert werden. Auch der finale Einsatz muss korrekt abgestimmt sein, damit das Modell auch wirklich so arbeitet, wie es vorgesehen war.
Die Überprüfung des Modells erfolgt deshalb über ein von IBM und fortiss entwickeltes Factsheet, das alle vier Schritte und alle Claims abdeckt sowie fortlaufend während des Prozesses aktualisiert wird. In diesem Factsheet werden alle relevanten Informationen festgehalten. Somit liefert es die Erklärung, weshalb so einem Modell vertraut werden kann. Ein vollständiges Beispiel unseres Factsheets für Federated Learning finden Sie auf der IBM Research AI FactSheets 360-Webseite.
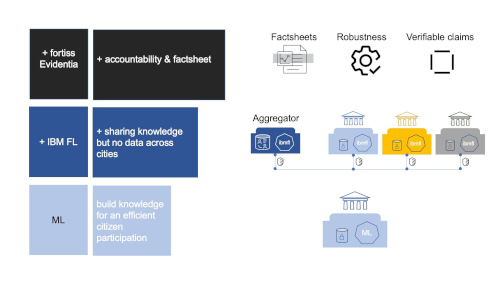
Accountability trotz Datenschutz
Bereits am Projektanfang wird festgelegt, welche konkreten Nachweise gespeichert und in das System eingegeben werden müssen. Diese Informationen werden dann überprüft und das Resultat fortlaufend im Factsheet festgehalten. Das System zeigt dem Auditor auf einen Blick an, welcher Claim überprüft wurde. Ebenfalls ob ein Problem aufgetreten ist oder alle Informationen den nötigen Standard entsprechen. So kann der Auditor alle relevanten Informationen erfassen und das Machine Learning-Modell verifizieren.
Vor allem in Bereichen, in denen strenge Regularien bezüglich des Datenschutzes bestehen und in denen mit sehr sensiblen Daten gearbeitet wird, ist es eine Herausforderung, ein Machine Learning-Modell nachvollziehbar zu gestalten. Federated Machine Learning ermöglicht, ein solches Modell zu erstellen, auch ohne die Rohdaten zentral zu speichern. Jedoch baut sich erst durch die Überprüfung durch individuell abgestimmte Claims und ein schlüssiges und lesbares Factsheet Vertrauen in den Algorithmus auf. IBM und fortiss forschen deshalb weiter gemeinsam an Wegen, Accountable Federated Machine Learning voranzutreiben.